
Last week I saw a social post about mortgage refixing. The question was simple enough to fit in one Instagram post, but real enough to matter: if you still have a low fixed mortgage rate for a while, does it make sense to refix now or wait until the current fixed period ends?
That caught my attention for obvious reasons. It also felt like a perfect small problem for a proper AI-assisted build. The scope was tight, the outcome was practical, and the logic could be checked. So I used it as an excuse to test a whole delivery loop at once: verifying formulas in ChatGPT, building a disposable prototype, pushing the design through Google Stitch, moving the result into a real repo with Codex constraints, and then wiring the whole thing into Git, preview deployments, and production delivery.
The app is live at hypo.dataworkers.eu. It runs entirely in the browser and does not collect data. No accounts, no backend, no analytics, no cookie banner. I hate cookie banners, so I was not going to build one just to tell people how much I hate them.
What made the experiment interesting was not the calculator itself. The calculator is small. What made it useful was that it let me test the whole chain from vague idea to something production-like. That is the part many people still underestimate. AI made first drafts absurdly cheap. It did not make delivery automatic.


The app started as a question, not as a framework choice
Before I touched a stack, I wanted to verify the underlying math. The original trigger was a practical decision problem, not a product brief: should I lock now or later, and under what future rate assumptions does the answer change?
So I went back to the formulas first. Part of that happened while sitting at the computer and part of it happened while walking with a stroller, which is honestly a good stress test for whether a workflow is actually lightweight. I used ChatGPT to check the formula from that post, pressure-test the assumptions, and get to a version I was comfortable turning into a small interactive tool.
That stage looks boring from the outside, but it mattered more than any later tool choice. Once the formula and assumptions were clearer, the MVP behavior got clearer too. The edge cases were easier to spot. The success criterion was easier to define. Teams skip this step all the time. They jump into architecture, generate screens, and only later discover that the product logic was still fuzzy.
The logic from the first prototype was simple enough to inspect and strong enough to carry forward: example-code/single-page-mortgage-refixer.html
The first real artifact was a disposable HTML file
Once the calculation was clear enough, I asked ChatGPT to produce a first prototype as a single self-contained HTML file. No framework, no build step, no repo structure, no styling system that had to survive the week. Just a file I could open in the browser and react to.
That file became the behavioral reference for everything that followed: example-code/single-page-mortgage-refixer.html
This is one of the highest-leverage moves in software delivery in general, not just in small AI projects. Any project can be broken down into smaller problems, and those smaller problems can often be verified with simple throwaway prototypes. That makes them useful far beyond early coding. They are a strong starting point for the analytical part of the work, for later UI and design decisions, and even for rough effort estimation. Once coding becomes cheaper, ambiguity gets more expensive. A disposable prototype gives everyone the same thing to look at and react to. It turns a fuzzy conversation into a concrete object. It also makes it much easier to say, "this part is right, this part is wrong, keep this behavior, throw away that layout."
I treated the prototype as disposable on purpose. That made it much easier to use it honestly. I did not need to protect it. I only needed it to teach me what the actual app had to do.
I used the prototype to generate the design prompt
After the HTML MVP started behaving correctly, I asked ChatGPT to generate a description of the app that I could feed into Google Stitch. That step turned out to be more useful than prompting Stitch from scratch, because the design input now had a concrete behavioral reference behind it.
Instead of saying "make me a mortgage app," I was effectively saying, "here is the app, here is what it does, now explore visual directions for this exact thing."
The results from Stitch were not the final product, but they were good enough to do two important jobs. First, they helped me explore visual directions quickly. Second, they gave me a durable design artifact I could carry forward into implementation. I exported the resulting design reference into: DESIGN.md

That changed the next stage completely. The point was no longer "have AI make something pretty." The point was to carry design intent forward in a form that implementation tooling could actually use. Without that, visual drift shows up almost immediately.
Then the work moved into a real repository
Once I had the formula, the disposable HTML MVP, and the Stitch design direction, I created a new repository on my machine and started setting up the actual operating environment.
This is where the experiment stopped being a toy. I added focused skills for
building with Deno 2.x and Fresh 2.x, because I did not want the model drifting
into generic Node-first habits. I used the app description as the basis for an
AGENTS.md file and made the constraints explicit: use Deno and Fresh, treat
DESIGN.md as the source for visual decisions, and do not consider a task
complete unless test, lint, and build are all green.
I also added Chrome DevTools MCP for browser inspection and Context7 for live documentation lookup. Again, the important point was not "more tools." It was that AI gets much more useful once the environment around it has clear rules and good access to the right context.
The repo-level instructions captured the core product intent and framework choices: AGENTS.md

This is the part that most "vibe coding" stories leave out. Raw prompting can generate a surprising amount of output. That is not the same as having a delivery setup that consistently gives you useful output.
I saved the earlier artifacts in the repo and used them as references
I saved the self-contained MVP HTML file into the repository as a functionality and algorithm reference. I also kept the Stitch output and screenshots there as design references. That separation mattered.
The HTML prototype was the answer to "what should this thing do?" The Stitch
output and DESIGN.md were the answer to "how should this feel and look?" Those
are related questions, but they are not the same question, and keeping them
separate made later prompting much cleaner.
From there I could prompt Codex with something much more specific: use the
single-file app as the behavior reference, use the Stitch output and DESIGN.md
as the design reference, and reimplement the whole thing properly in Fresh.
The break-even logic from the original MVP also carried over directly:

Git, cloud Codex, and Deno Deploy were the actual speed multiplier
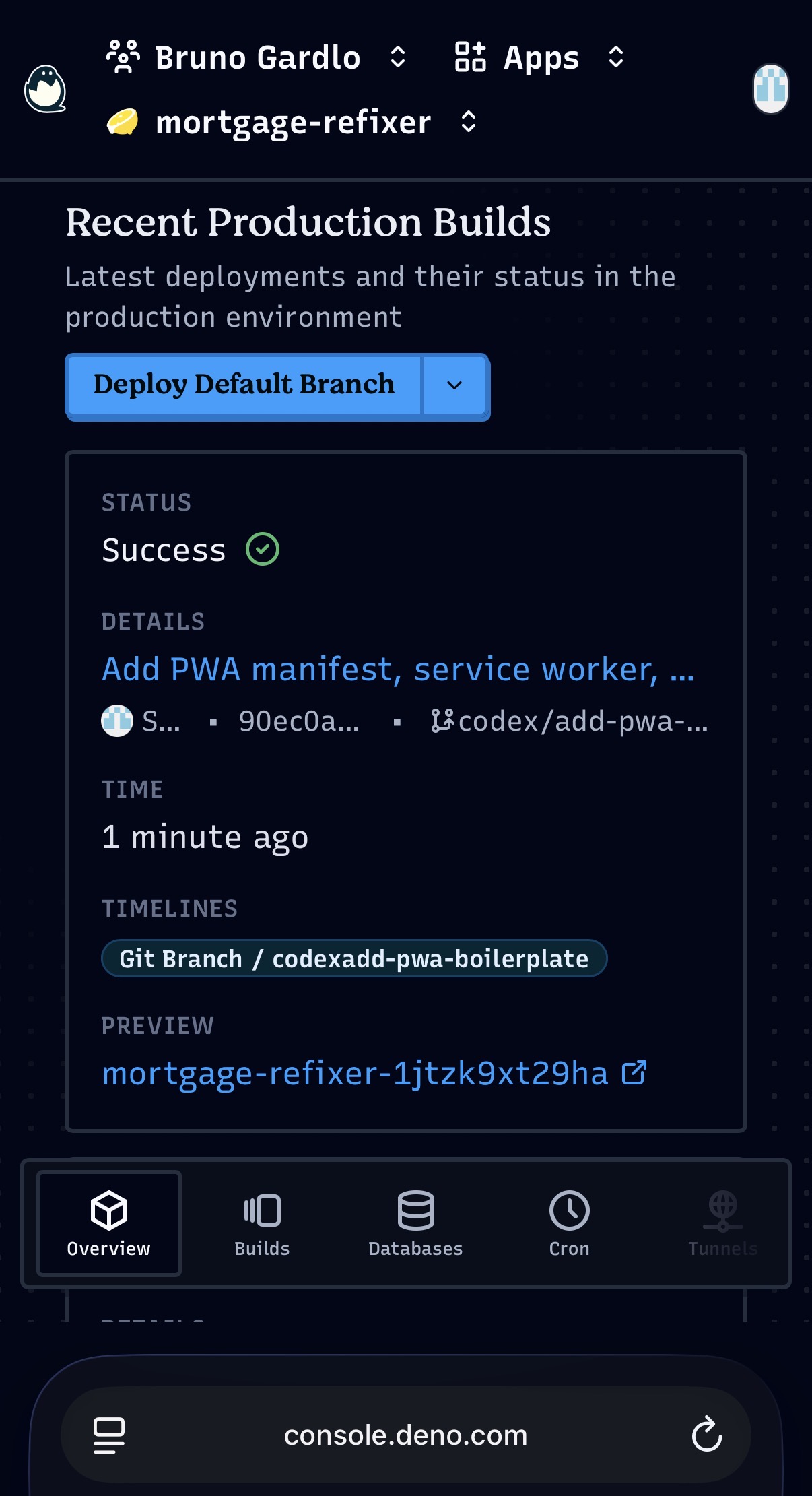
I initialized Git, pushed the repo online, and connected cloud Codex so it could work directly against the repository. I also set up Deno Deploy with a custom subdomain. This is where the whole thing started to feel much less like a demo and much more like a real delivery chain.
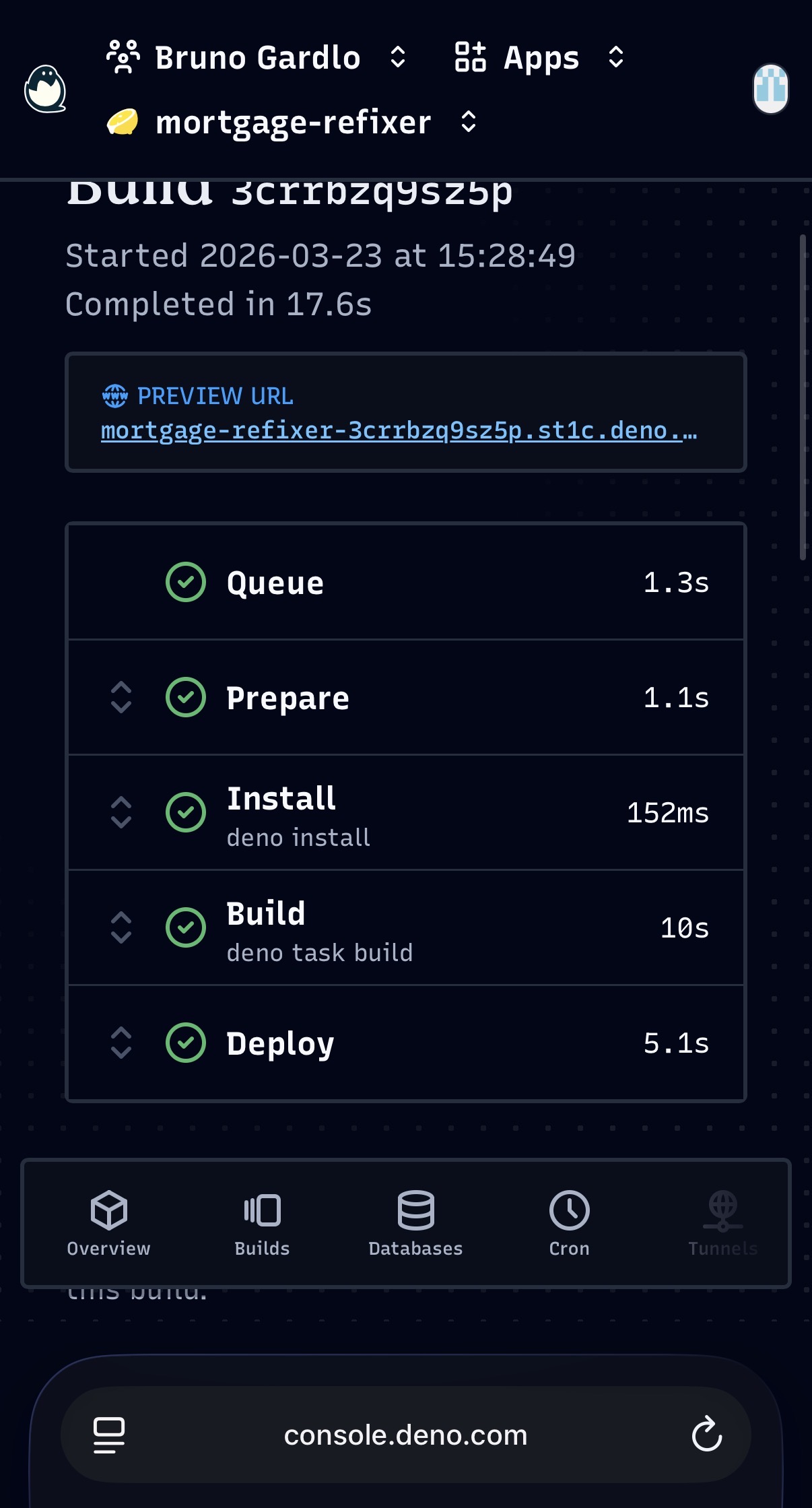
The important detail is that Deno Deploy does not just give you production
hosting. It also gives you the fast feedback loop that makes AI-assisted
delivery really usable: preview deployments for pull requests and production
deployment from main.
Once that loop exists, a change request becomes a pull request, a preview link, a review decision, and then a production deployment. That system matters more than any single model capability, because it turns local code generation speed into something you can actually validate and trust.
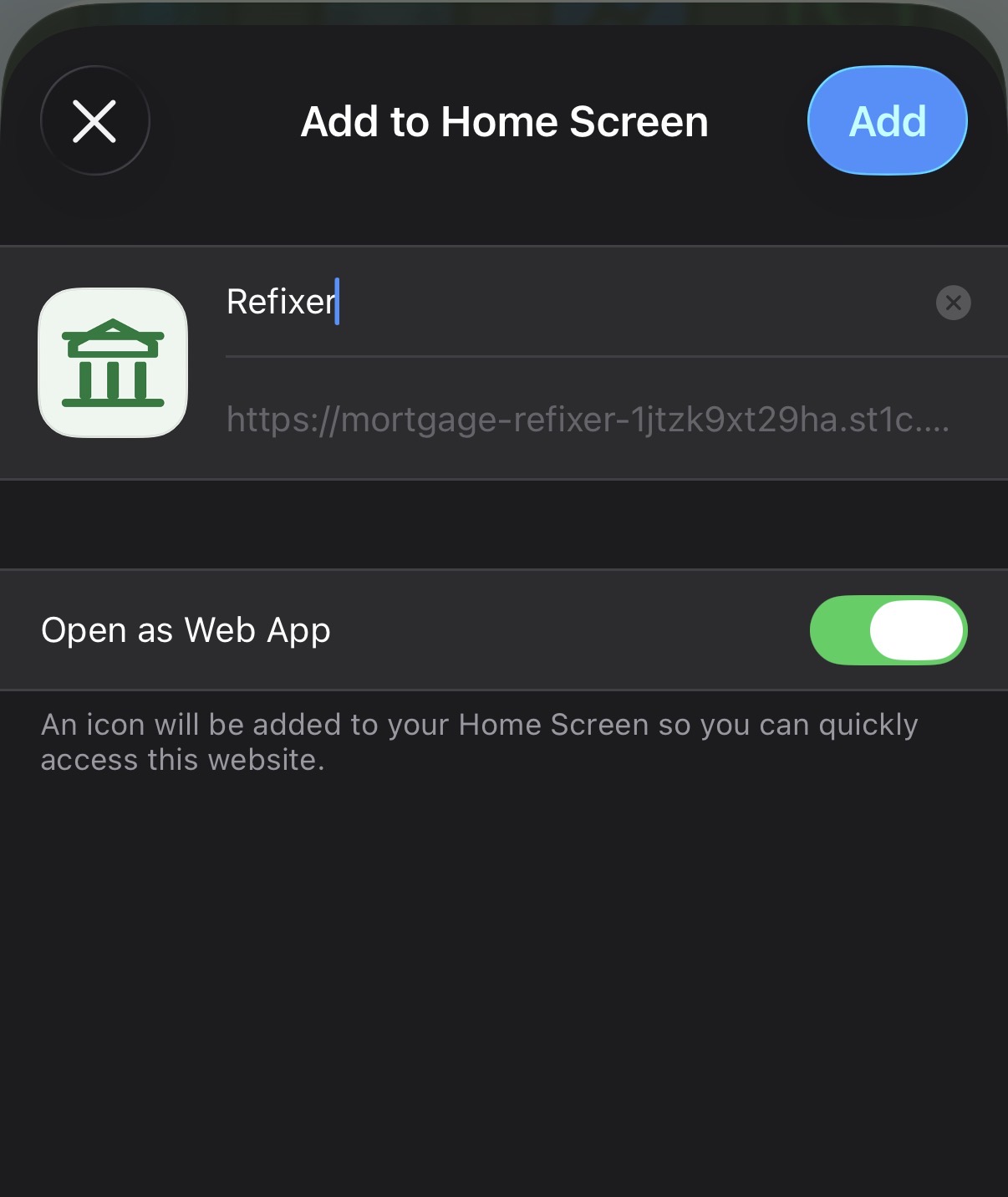
That is also what made mobile work realistic. At that point I could dictate
changes to Codex from my phone, let it create or update the pull request, open
the Deno Deploy preview on the same device, verify the change on the actual end
device, and then merge to main for automatic deployment. Going from mobile
Codex to live production in seconds still feels a bit absurd, but it works
because the whole chain exists around it.
The screenshots from this stage tell the story better than generic "AI is fast" claims ever could:
The broader point is not the mortgage app
The bigger lesson here is that this is how software should be built at any scale, even if every individual tool and process detail needs to be adapted for a larger team.
You start by shaping the specification until the problem is concrete. You create artifacts that make the intended behavior visible. You keep implementation connected to those artifacts. You review changes as pull requests. You validate them in preview environments. You rely on CI and CD so production is a merge, not a ceremony. And you make it cheap to iterate on the actual end-user behavior instead of discussing abstractions forever.
That is why I keep coming back to the same point: poor specs are still one of the biggest causes of delivery drag, and AI does not remove that problem. If anything, it makes the cost of vague thinking show up sooner. The same DORA pattern applies here too. AI can improve throughput while instability goes up. The teams that benefit are the ones pairing fast generation with strong version control, small batches, visible delivery flow, and reliable feedback loops.
This tiny project made that obvious. Writing code got easier very quickly. Building a system where that speed stayed useful required much more deliberate structure.
Where AI still needed a human to steer it
AI accelerated implementation, but it did not remove the hard calls. Those still depended on experience.
In my case, the places where I had to steer aggressively were the parts that determine whether the app feels real or flimsy: choosing the framework and deployment setup, defining the test rules, setting up the skills and MCP tooling, making the user flow coherent, fixing accessibility issues, pushing toward four perfect Lighthouse scores, defining the font and glyph usage, specifying the PWA requirements, and then grinding through the visual inconsistencies and bugs that always show up once a product gets close to release.
That final stretch is where seniority still matters most. Not because AI cannot type code, but because someone still has to decide what "done" means, what quality bar is acceptable, what to simplify, what to ignore, what has to be corrected now, and what risk is worth carrying.
Closing
What I like about this project is that it was small enough to finish and honest enough to be instructive. It was not a grand product launch. It was one practical app and one complete delivery chain.
The chain was the real lesson: verify the formula, build the disposable prototype, use that to drive design, encode constraints before scaling implementation, wire the work into Git and preview deployments, and then use experience to steer the final quality.
That is the part I think scales. Not the novelty of a mortgage calculator, and not the novelty of doing some of the work from a phone. The durable part is the delivery setup: better specs, better artifacts, faster reviews, preview validation on the target device, and production deployment as a routine outcome instead of a stressful event.