
Agentic tools became mainstream less than a year ago, and the footprints are already obvious.
Open LinkedIn for five minutes and you will see cloned posts: same emojis, same cadence, same fake "curious what you think?" ending.
Open AI-generated app galleries. You will see similar gradients, similar card layouts, similar hero sections, similar "modern SaaS" typography.
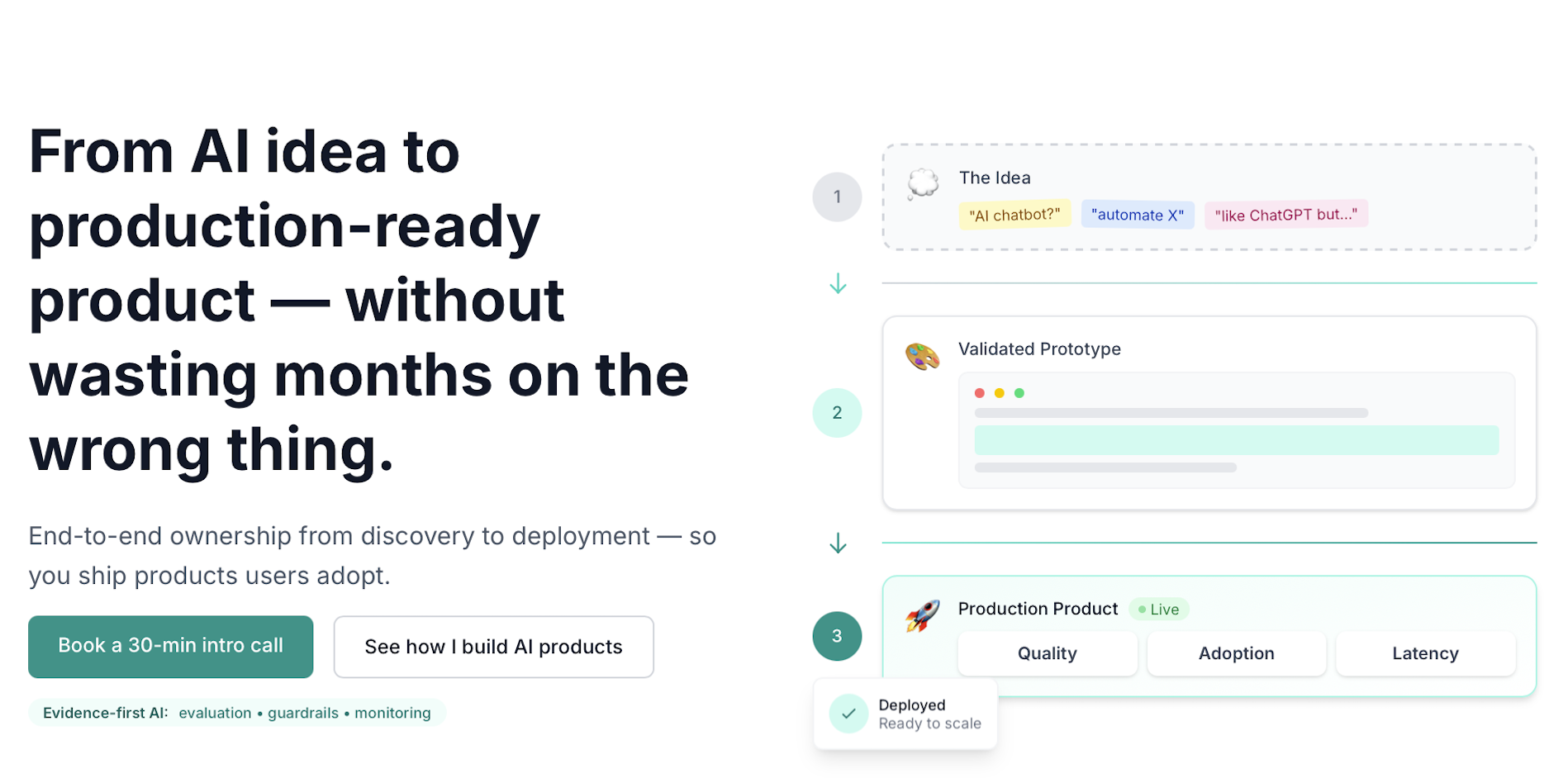
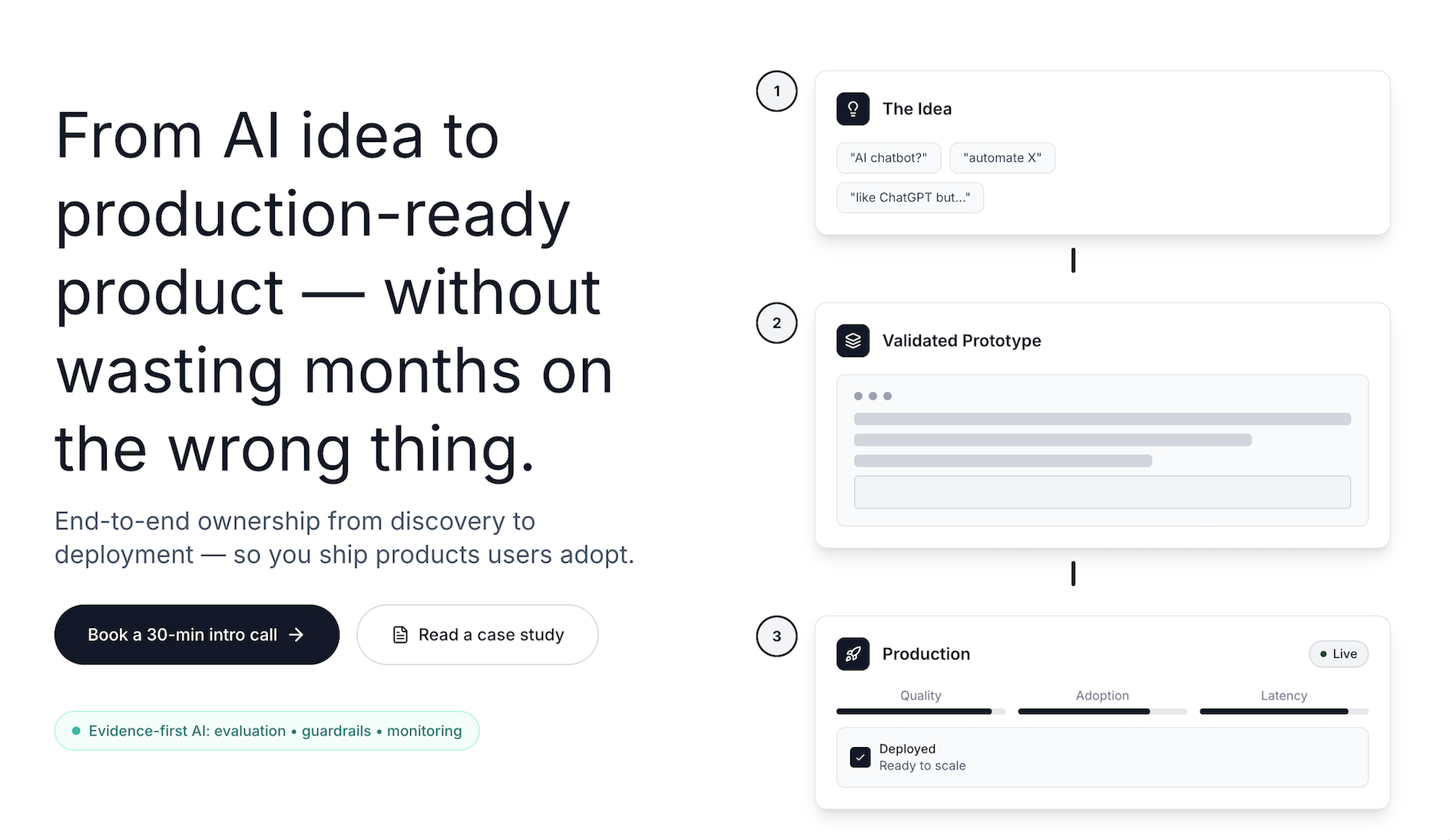
I keep seeing this same hero pattern (rectangular shapes, tiny detail treatment, and very similar color/gradient combinations) across public websites in near-identical copies.
Look at generated code and the pattern repeats: clean-looking scaffolds, weak boundaries, and the same hidden mistakes. This is not surprising - it is exactly how these models work.
Why everything starts to look the same
LLMs generate the most probable next token. They are optimized for plausibility, not originality.
That gives us speed. It also pulls output toward the statistical middle. When millions of users ask similar prompts, outputs converge.
The model is not trying to be original. It is trying to produce the most likely continuation. That is why you keep seeing:
- the same rhetorical patterns in posts
- the same UX patterns in generated designs
- the same architecture defaults in generated code
There is only so much training data, so many parameters, and so many recurring prompt templates. At scale, convergence is expected.
Where this hurts
People notice text uniformity first, because it is visible.
Specific example from my LinkedIn thread today: three posts with different content, but a very similar template. The AI fingerprints are directly visible: emoji bullets, repeated end-of-post engagement prompts, and near-identical phrasing patterns.
Design uniformity is also obvious: same layout rhythm, same color logic, same interactions.
Code uniformity is harder to spot early. It usually appears later as:
- weak boundaries
- shallow error handling
- copy-paste architecture
- expensive maintenance
AI can accelerate delivery. It can also accelerate technical debt.
The uncomfortable part
There are ways to avoid this. Most teams do not use them.
Not because they are hard. Because they require discipline.
You need taste, constraints, review loops, and the discipline to rewrite what the model gives you. That is real work. Most people skip it.
So here is the line I keep coming back to:
AI is a great multiplier for skill. It is also a great multiplier for laziness.
How to avoid AI look-alike output
If you want output that feels like yours, do this on purpose.
- Write a real brief. Include audience, constraints, non-goals, and failure modes.
- Add negative constraints. Explicitly ban cliches, default UI kits, filler language, and overbuilt code.
- Ask for alternatives, not one polished answer. Force tradeoffs. Force disagreement. Force second options.
- Edit manually every time. Tighten claims, cut fluff, and rewrite weak sections in your own voice.
- Keep your own style system. Text voice, design tokens, spacing rules, interaction principles.
- Treat generated code as draft code. Review tests, error paths, observability, and operational behavior.
Quick quality check
Before publishing content, shipping a design, or merging generated code, ask:
- Would I recognize this as ours without the logo?
- Did we make at least three non-obvious choices?
- Did we remove default model filler?
- Did a human challenge assumptions and edge cases?
If the answer is no, you are probably shipping the model default.
Final point
AI is not the problem. Autopilot usage is.
Use AI as a thinking partner and execution accelerator. Do not use it as a substitute for judgment.
Convenience is addictive. Originality still comes from deliberate choices and attention to detail.